در ماه فوریه، زمانی که مارک زاکربرگ، مدیرعامل متا اعلام کرد که این شرکت در حال کار بر روی طیف وسیعی از ابتکارات هوش مصنوعی جدید است، او خاطرنشان کرد که در میان این پروژهها، متا در حال توسعه جدید است. تجربه با متن، تصاویر، و همچنین با عناصر ویدئویی و “چند وجهی”.
بنابراین «چند وجهی» در این زمینه به چه معناست؟
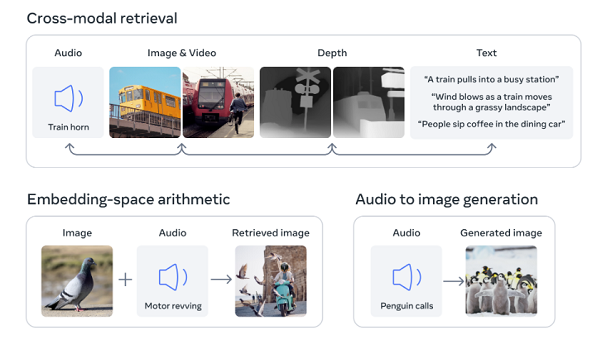
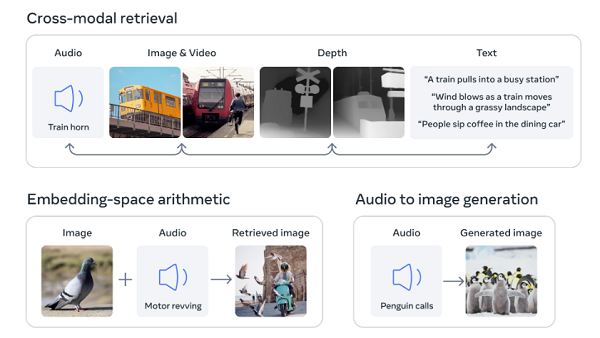
امروز، متا با راهاندازی ImageBind، فرآیندی که سیستمهای هوش مصنوعی را قادر میسازد تا ورودیهای متعدد را برای توصیههای دقیقتر و پاسخگوتر درک بهتری داشته باشند، توضیح داده است که چگونه هوش مصنوعی چندوجهیاش میتواند کار کند.
همانطور که توسط متا توضیح داده شده است:
“زمانی که انسان اطلاعات جهان را جذب می کند، ما ذاتا از حواس متعددی مانند دیدن یک خیابان شلوغ و شنیدن صدای موتور خودروها استفاده می کنیم. امروز، ما رویکردی را معرفی میکنیم که ماشینها را یک قدم به توانایی انسان برای یادگیری همزمان، جامع و مستقیم از بسیاری از اشکال مختلف اطلاعات نزدیکتر میکند – بدون نیاز به نظارت صریح. ImageBind اولین مدل هوش مصنوعی است که قادر به اتصال اطلاعات از شش حالت است.
را فرآیند ImageBind اساساً سیستم را قادر می سازد تا نه تنها بین متن، تصویر و ویدئو، بلکه صدا و همچنین عمق (از طریق سنسورهای سه بعدی) و حتی ورودی های حرارتی، ارتباط را یاد بگیرید. در ترکیب، این عناصر میتوانند نشانههای فضایی دقیقتری را ارائه دهند، که سپس میتواند سیستم را قادر به تولید نمایشها و تداعیهای دقیقتر کند، که تجربیات هوش مصنوعی را یک قدم به تقلید پاسخهای انسانی نزدیکتر میکند.
برای مثال، با استفاده از ImageBind، صحنه ساخت متا می تواند تصاویری از صدا ایجاد کند، مانند ایجاد یک تصویر بر اساس صداهای یک جنگل بارانی یا یک بازار شلوغ. سایر احتمالات آینده شامل راههای دقیقتر برای تشخیص، اتصال، و تعدیل محتوا و تقویت طراحی خلاقانه، مانند تولید رسانههای غنیتر بهطور یکپارچهتر و ایجاد عملکردهای جستجوی چندوجهی گستردهتر است.”
موارد استفاده بالقوه قابل توجه است، و اگر سیستمهای متا بتوانند تراز دقیقتری بین این ورودیهای متغیر ایجاد کنند، میتواند فهرست فعلی ابزارهای هوش مصنوعی را که مبتنی بر متن و تصویر هستند، به یک قلمرو کاملاً جدید از تعامل ارتقا دهد.
که همچنین میتواند ایجاد جهانهای واقعیت مجازی دقیقتر را تسهیل کند، عنصری کلیدی در پیشروی متا به سمت متاورس. برای مثال، از طریق Horizon Worlds، افراد میتوانند فضاهای VR خود را ایجاد کنند، اما محدودیتهای فنی این فضاها، در این مرحله، به این معنی است که بیشتر تجربیات Horizon هنوز بسیار ابتدایی هستند – مانند قدم زدن در یک بازی ویدیویی از دهه 80.
اما اگر متا بتواند ابزارهای بیشتری را فراهم کند که هر کسی را قادر میسازد هر آنچه را که میخواهد در VR ایجاد کند، به سادگی با بیان آن، میتواند یک قلمرو کاملاً جدید از امکان را تسهیل کند، که میتواند به سرعت تجربه VR آن را به گزینهای جذابتر و جذابتر برای بسیاری تبدیل کند. کاربران
ما هنوز به آنجا نرسیدهایم، اما پیشرفتهایی مانند این به سمت مرحله بعدی توسعه متاورس حرکت میکنند و دقیقاً به این نکته اشاره میکنند که چرا Meta در پتانسیل تجربههای فراگیرتر خود بسیار بالاست.
متا همچنین اشاره میکند که ImageBind میتواند در راههای فوریتر برای پیشبرد فرآیندهای درونبرنامه استفاده شود.
تصور کنید که کسی میتواند یک فیلم ضبطشده از غروب اقیانوس بگیرد و فوراً یک کلیپ صوتی عالی را برای بهبود آن اضافه کند، در حالی که تصویر یک شی تزو میتواند مقالهها یا مدلهای عمقی سگهای مشابه را ارائه دهد. یا زمانی که مدلی مانند Make-A-Video ویدیویی از یک کارناوال تولید میکند، ImageBind میتواند نویز پسزمینه را برای همراهی آن پیشنهاد کند و تجربهای فراگیر ایجاد کند.”
اینها استفاده های اولیه از این فرآیند هستند و می تواند یکی از پیشرفت های مهم در فرآیند توسعه هوش مصنوعی متا باشد.
اکنون منتظر می مانیم و ببینیم که متا چگونه آن را اعمال می کند و آیا این به تجربه های جدید واقعیت افزوده و واقعیت مجازی در برنامه هایش منجر می شود یا خیر.
در اینجا می توانید اطلاعات بیشتری در مورد ImageBind و نحوه عملکرد آن بخوانید.