
متا به دنبال کمک به محققان هوش مصنوعی است که ابزارها و فرآیندهای خود را با انتشار مجموعهای از مجموعه دادههای جدید از کلیپهای ویدیویی چهره به چهره، که شامل طیف گستردهای از افراد مختلف میشود، فراگیرتر کنند. توسعه دهندگان ارزیابی می کنند که مدل های آنها چقدر برای گروه های جمعیتی مختلف کار می کند.
امروز ما نسخه 2 مکالمات گاه به گاه منبع باز هستیم – مجموعه داده ای مبتنی بر رضایت از مونولوگ های ضبط شده که شامل ده مقوله ارائه شده و حاشیه نویسی شده است که محققان را قادر می سازد عادلانه و استحکام مدل های هوش مصنوعی را ارزیابی کنند.
جزئیات بیشتر در مورد این مجموعه داده جدید ⬇️
– هوش مصنوعی متا (@MetaAI) 9 مارس 2023
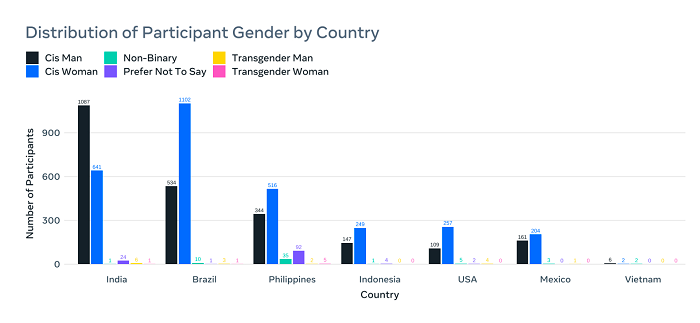
همانطور که در این مثال می بینید، پایگاه داده مکالمات گاه به گاه متا نسخه 2 شامل 26467 مونولوگ ویدیویی است که در هفت کشور ضبط شده است و شامل 5567 شرکت کننده پولی می شود، همراه با داده های گفتاری، بصری و ویژگی های جمعیت شناختی برای اندازه گیری اثربخشی سیستماتیک.
طبق متا:
“مجموعه داده مبتنی بر رضایت توسط a اطلاعات و شکل داده شد بررسی ادبیات جامع حول دسته های جمعیتی مربوطه، و با مشورت کارشناسان داخلی در زمینه هایی مانند حقوق شهروندی ایجاد شده است. این مجموعه داده یک لیست دانه بندی از 11 دسته بندی ارائه شده و حاشیه نویسی برای اندازه گیری بیشتر عدالت و استحکام الگوریتمی در این سیستم های هوش مصنوعی ارائه می دهد. طبق اطلاعات ما، این اولین مجموعه داده منبع باز با ویدیوهای جمع آوری شده از چندین کشور با استفاده از اطلاعات جمعیت شناختی بسیار دقیق و دقیق برای کمک به آزمایش مدل های هوش مصنوعی برای انصاف و استحکام است.”
به “رضایت محور” توجه کنید. متا کاملاً واضح است که این داده ها با مجوز مستقیم از شرکت کنندگان به دست آمده است و به طور مخفیانه منبع آن نبوده است. بنابراین، اطلاعات فیسبوک شما یا ارائه تصاویر از IG نیست – محتوای موجود در این مجموعه داده برای به حداکثر رساندن گنجاندن با ارائه نمونههای بیشتری از افراد با طیف گستردهای از پیشینهها به محققان هوش مصنوعی طراحی شده است تا در مدلهای خود استفاده کنند.
جالب توجه است که اکثر شرکت کنندگان از هند و برزیل، دو اقتصاد دیجیتال نوظهور، که نقش مهمی در مرحله بعدی توسعه فناوری خواهند داشت، آمده اند.
مجموعه داده جدید به توسعهدهندگان هوش مصنوعی کمک میکند تا نگرانیهای مربوط به موانع زبان، همراه با تنوع فیزیکی را که در برخی زمینههای هوش مصنوعی مشکلساز بوده است، برطرف کنند.
به عنوان مثال، برخی از ابزارهای پوشش دیجیتال به دلیل محدودیت در مدلهای آموزشی خود قادر به تشخیص ویژگیهای کاربر خاص نیستند، در حالی که برخی از آنها به عنوان نژادپرست آشکار برچسبگذاری شدهاند، حداقل تا حدی به دلیل محدودیتهای مشابه.
این یک تاکید کلیدی در مستندات متا از مجموعه داده جدید است:
با افزایش نگرانیها در مورد عملکرد سیستمهای هوش مصنوعی در مقیاسهای مختلف رنگ پوست، تصمیم گرفتیم از دو مقیاس مختلف برای حاشیهنویسی رنگ پوست استفاده کنیم. اولین مورد مقیاس شش رنگ فیتزپاتریک است که به دلیل سادگی و استفاده گسترده، رایج ترین طرح طبقه بندی عددی برای رنگ پوست است. دوم مقیاس 10 رنگ پوست است که توسط گوگل معرفی شده و در خدمات جستجو و عکس آن استفاده می شود. گنجاندن هر دو مقیاس در مکالمات گاه به گاه نسخه 2 مقایسه واضحتری با آثار قبلی که از مقیاس فیتزپاتریک استفاده میکردند فراهم میکند و در عین حال اندازهگیری را بر اساس مقیاس فراگیرتر Monk امکانپذیر میکند.”
این یک ملاحظات مهم است، به خصوص که ابزارهای مولد هوش مصنوعی همچنان به شتاب گرفتن ادامه می دهند و شاهد افزایش استفاده در بسیاری از برنامه ها و پلتفرم های بیشتر هستند. برای به حداکثر رساندن گنجاندن، این ابزارها باید بر روی مجموعه داده های توسعه یافته آموزش ببینند، که تضمین می کند همه در چنین پیاده سازی در نظر گرفته می شوند و هر گونه نقص یا حذف قبل از انتشار شناسایی می شود.
مجموعه دادههای مکالمات گاه به گاه متا به این امر کمک میکند و میتواند یک مجموعه آموزشی بسیار ارزشمند برای پروژههای آینده باشد.
در اینجا می توانید اطلاعات بیشتری در مورد پایگاه داده Meta’s Casual Conversations v2 بخوانید.